| Page 6 out of 30 Pages |
Refer to Exhibit: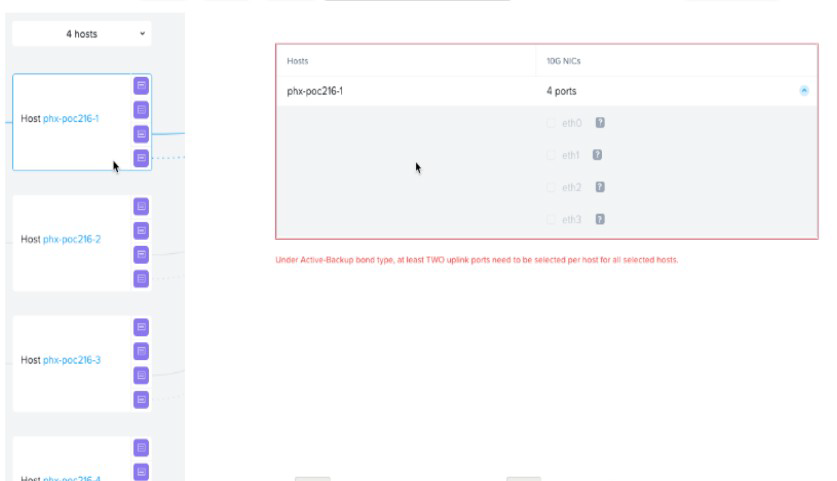
An administrator is attempting to create an additional virtual switch on a newly deployed
AHV cluster, using the two currently disconnected interfaces. The administrator is unable to
select the disconnected interfaces when creating the virtual switch.
What is the likely cause of this issue?
A. Only one interface is available on the selected hosts.
B. Interfaces must be connected to the network before they can be assigned.
C. The disconnected interfaces are currently assigned to virtual switch 0,
D. Interfaces must be assigned to virtual switches via the cli
Explanation: In Nutanix AHV, when creating a virtual switch and trying to add network
interfaces (NICs) to it, the NICs must be connected to the network before they can be
selected and assigned to the switch. If the interfaces are showing as disconnected, the
system will not allow them to be added to a virtual switch because it cannot verify their
operational status or the presence of a live network connection.
It is a standard requirement for the interfaces to have physical connectivity (i.e., network
cables plugged in and connected to a live switch port) so that the AHV host can detect the
link status as up. Once the interfaces are connected and recognized by the host, they can
then be added to a virtual switch in the Nutanix AHV.
It's important to note that while the command-line interface (CLI) is indeed a powerful tool
for managing network configurations on AHV hosts, and some configurations do indeed
require CLI, the inability to select disconnected interfaces is not specifically a limitation that
requires the use of CLI to overcome. The focus should be on ensuring that the physical
connectivity is established for the interfaces in question.
This behavior is consistent with networking best practices and Nutanix's network
configuration guidelines, as detailed in the Nutanix AHV Networking Guide. This guide
explains the requirements and procedures for configuring virtual switches and managing
NICs in a Nutanix AHV environment.
Refer to Exhibit: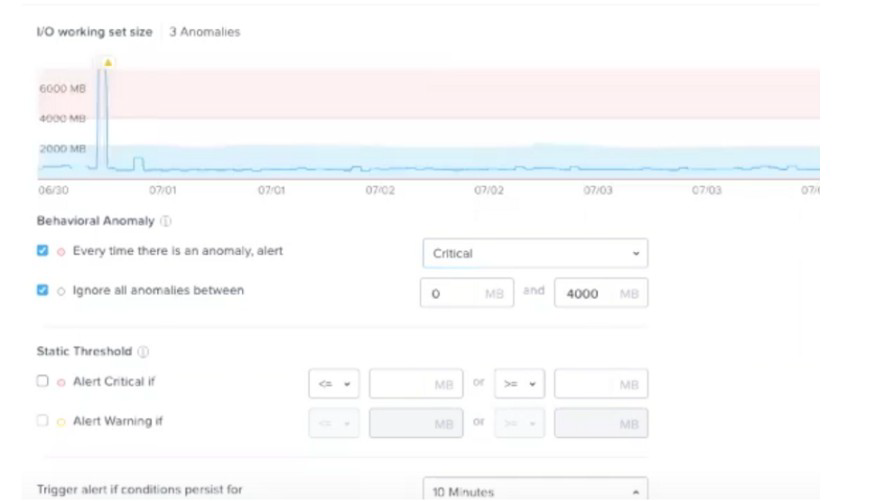
Which statement is true?
A. A critical alert will be triggered if I/O working set size goes over 6000 MB.
B. A critical alert will be triggered when there is an anomaly above 4000 MB.
C. A warning alert will be triggered after 3 anomalies have been catch.
D. A warning alert will be triggered if I/O working set size goes over the blue band.
Explanation:
A. This statement is incorrect because there is no static threshold set to trigger a critical
alert at 6000 MB. The graph shows a peak that goes above 6000 MB, but the alert
configuration below does not specify a static threshold at this value.
B. This is the correct statement. The configuration under "Behavioral Anomaly" is set to
alert every time there is an anomaly, with a critical level alert set to trigger when the I/O
working set size is between 0 MB and 4000 MB. The graph illustrates that the anomalies
(highlighted in pink) occur when the working set size exceeds the normal range (blue
band). Therefore, any anomaly detected above 4000 MB would trigger a critical alert.
C. This statement is incorrect because there is no indication that a warning alert is
configured to trigger after 3 anomalies. The exhibit does not show any configuration that
specifies an alert based on the number of anomalies.
D. This statement is incorrect as there's no indication that a warning alert will be triggered
based on the I/O working set size exceeding the blue band. The alert settings are
configured to ignore anomalies below 4000 MB and to trigger a critical alert for anomalies
above this threshold.
The settings displayed in the exhibit are typically part of Nutanix's Prism infrastructure
management platform, which can set various thresholds for performance metrics and
trigger alerts based on those thresholds. The behavior is defined in the Prism
documentation where the alert configuration is outlined.
An administrator wants to expand the Failure Domain level of a cluster. What two options are available? (Choose two.)
A. Node
B. Data Center
C. Block
D. Rack
Explanation: Nutanix clusters are resilient to a drive, node, block, and rack failures because they use redundancy factor 2 by default, allowing Nutanix clusters to selfheal2. Failure scenarios can be thought of in terms of fault domains, which are the physical or logical parts of a computing environment or location that are adversely affected when a device or service experiences an issue or outage3. There are four fault domains in a Nutanix cluster: Disk, Node, Block, and Rack4. Block and Rack are two options that are available for expanding the failure domain level of a cluster. Block fault tolerance is enabled by default and ensures that data is replicated across different blocks in a cluster5. Rack fault tolerance has to be configured manually and ensures that data is replicated across different racks in a cluster4.
What is the expected behavior of the VMs residing on that host when a controller VM becomes unavailable?
A. A Live Migration will be performed on the affected VMs.
B. The host will automatically redirect I/O and VMs will continue running.
C. The impacted host and VMs will automatically shut down.
D. VM High Availability will restart the impacted VMs on another host
Explanation: According to the Nutanix Support & Insights web search result1, if the owner Controller VM becomes unavailable, the address moves to another Controller VM, ensuring that it is always available. This IP address is also used as a cluster-wide address by clients configured as part of Nutanix Files and other products. Therefore, the host will automatically redirect I/O and VMs will continue running without any interruption.
Refer to the Exhibit:
An administrator is adding a new node to a cluster. The node has been imaged to the same
versions of AHV and AOS that the cluster is
running, configured with appropriate IP addresses, and br0-up has been configured in the
same manner as the existing uplink bonds.
When attempting to add the node to the cluster with the Expand Cluster function in Prism,
the cluster is unable to find the new node.
Based on the above output from the new node, what is most likely the cause of this issue?
A. There is a firewall blocking the discovery traffic from the cluster.
B. The ports on the upstream switch are not configured for LACP
C. The existing cluster and the expansion node are on different VLANs.
D. LACP configuration must be completed after cluster expansion
Explanation: The output in the exhibit indicates that the node's network interfaces (eth0-
eth3) are bonded together using LACP (Link Aggregation Control Protocol) with 'balancetcp'
as the bonding mode and LACP speed set to 'fast'. For LACP to function correctly, the
switch ports to which the node is connected must also be configured to support LACP. If
the ports on the upstream switch are not configured for LACP, the bond will not be able to
establish properly, and the node will not communicate effectively on the network, making it
undiscoverable when attempting to expand the cluster.
The absence of an operational LACP configuration could prevent the new node from joining
the existing cluster as the node's network interfaces would not be able to pass traffic
correctly. This can be verified by checking the switch configuration to ensure that the ports
are set to participate in an LACP bond.
The other options, such as a firewall blocking discovery traffic (Option A) or the node being
on different VLANs (Option C), are possible causes for a node not being discovered, but
given the specific command output provided, the most likely cause is related to the switch
port configuration for LACP. Option D, regarding completing LACP configuration after
cluster expansion, is not correct because LACP needs to be operational for the node to
communicate with the cluster during the expansion process.
Proper LACP configuration is critical for network communication in a Nutanix AHV cluster,
and this is covered in detail in the Nutanix AHV and Networking documentation. It outlines
the steps for configuring network bonds and LACP on both the AHV hosts and the
connecting network infrastructure.
Which component is supported by Prism Central storage policies?
A. Virtual Machines
B. Volume Groups
C. VM Templates
D. Storage Containers
Explanation: According to the Nutanix Prism Central Guide, Prism Central allows you to apply storage policies on a per VM basis using Category, so that the VM uses the storage configuration defined in the storage policy. Using a storage policy, you can manage parameters of VMs, such as encryption, type of or lack of data compression, and IOPS or Throughput throttling values to be applied to the entities.
| Page 6 out of 30 Pages |
| Nutanix NCP-MCI-6.5 Practice Questions Home | Previous |