| Page 2 out of 51 Pages |
How should a consultant verify that a Nutanix cluster can tolerate a single-node failure?
A. [root@cvm~]# ncli cluster get-domain-fault-tolerance-status type=node
B. nutanix@cvm~$ ncli cluster get-domain-fault-tolerance-status type=node
C. [root@avh~]# ncli cluster fault-tolerance-status type=node
D. nutanix@cvm~$ ncli cluster status type=node
Explanation: To verify that a Nutanix cluster can tolerate a single-node failure, the consultant should use the command nutanix@cvm~$ ncli cluster get-domain-fault-tolerance-status type=node. This command is executed from the Controller Virtual Machine (CVM) and checks the cluster's fault tolerance status specifically for node failures, providing insights into how the cluster's data resiliency and redundancy configurations are holding up against potential single-node failures.
The consultant is deploying a 20-node AHV cluster, as part of a Nutanix Files deployment. How many FSVMs can the consultant deploy in this environment?
A. 16
B. 18
C. 20
D. 22
Explanation: In a Nutanix Files deployment within a 20-node AHV cluster, the consultant can deploy a maximum of 16 FSVMs (File Server Virtual Machines). This limitation is based on Nutanix's best practices and design considerations for scalability and performance. The number of FSVMs that can be effectively managed and maintained without degrading the performance of the file-serving operations or the underlying storage infrastructure dictates this maximum.
Refer to the exhibit.
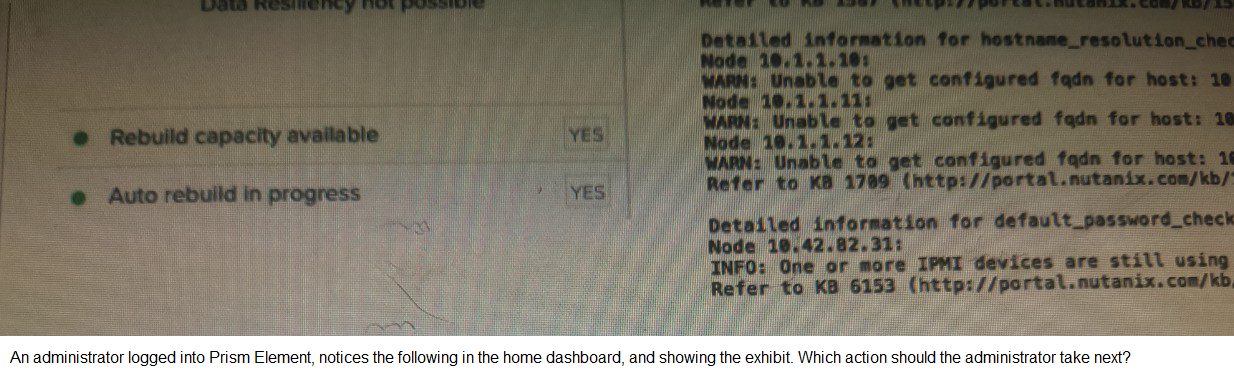
A. Configure the fqdn for the hosts indicated
B. Troubleshoot the zookeeper server issue
C. Re-run NCC specifying data_resiliency_check
D. Check the hardware page for disk failures
Explanation: The exhibit shows a screenshot of a Prism Element home dashboard with a notification that “Data Resiliency not possible” and warnings about the inability to get configured fully qualified domain names (fqdn) for hosts identified by their node numbers. In this scenario, the administrator should take action A: Configure the fqdn for the hosts indicated. This is because the warnings on hostname resolution indicate issues with fully qualified domain names (fqdn) configuration for specific nodes. Configuring the fqdn for these hosts can help resolve these issues and improve the data resiliency of the Nutanix cluster1.
A consultant has completed a cluster build according to the following requirements:
• Syslog Setup with ERROR level Logging
• Proxy Setup
• SNMP v3 Trap setup
When adding the cluster to an existing Prism Central with a proxy setup, the following error
is triggered in the Prism Gateway logs:
Caused by: corn.nutanix.util .base.ValidationException: Prism Central is unreachable
What configuration is likely missing?
A. Whitelist of Prism Central OSIP inside of Prism Element and all Prism Element CVMs inside of Prism Central
B. Whitelist of Prism Central VIP inside of Prism Element and Prism Element VIP inside of Prism Central
C. Whitelist of AHV Host IP addresses in Prism Central
D. Whitelist of Prism Central DSIP inside of Prism Element
Explanation: The error stating "Prism Central is unreachable" when trying to add a cluster to an existing Prism Central with a proxy setup is likely due to incorrect or missing network routing configurations or firewall rules that do not allow communication between Prism Element and Prism Central. The most likely configuration that is missing and needed to resolve this issue is the whitelist of Prism Central VIP inside of Prism Element and Prism Element VIP inside of Prism Central. Whitelisting these Virtual IP addresses ensures that network traffic between these crucial components of the Nutanix architecture is permitted, thus enabling successful communication and registration of the cluster with Prism Central.
Refer to the exhibit.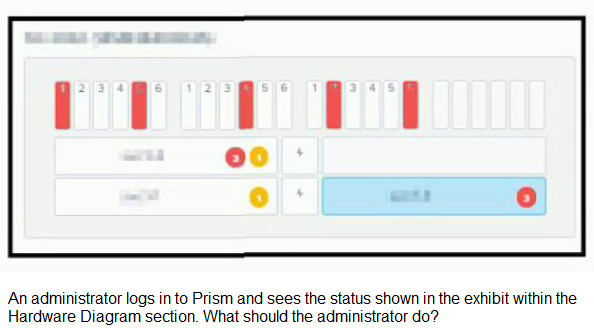
A. Resolve all alerts and re-import the disks to make sure there is no service disruption.
B. Restart all CVMs for the cluster to check, confirm health and repartition and add the disks.
C. Reseat all disks immediately. If this does not help, reseat the nodes.
D. Check status of applications running on the cluster and call support
A VDI environment based on AHV Cluster is not performing well. The current environment is using only one bridge (Bridge0). The administrator needs to verify if nodes are using all network cards associated to Bridge0. Which two menus should be used to check the current configuration? (Choose two.)
A. Network Configuration item in Settings menu
B. Host view in Network menu
C. Host NICs tab in Hardware menu
D. I/O Metrics tab in VM menu
| Page 2 out of 51 Pages |
| Nutanix NCS-Core Practice Questions Home |